Memory leak in cv.Moments, cv.PolyLine (Bug #489)
Added by Daniele Paganelli over 14 years ago.
Updated about 14 years ago.
| Status: | Done | Start date: | |
|---|---|---|---|
| Priority: | High | Due date: | |
| Assignee: | % Done: | 0% |
|
| Category: | python bindings | ||
| Target version: | - | ||
| Affected version: | Operating System: | ||
| Difficulty: | HW Platform: | ||
| Pull request: |
Description
The following python code will generate a memory leak:
from numpy import random, array
import cv
x=random.rand(50000)
y=random.rand(50000)
seq=array([x, y]).transpose()
for i in range(100):
cv.Moments(seq)
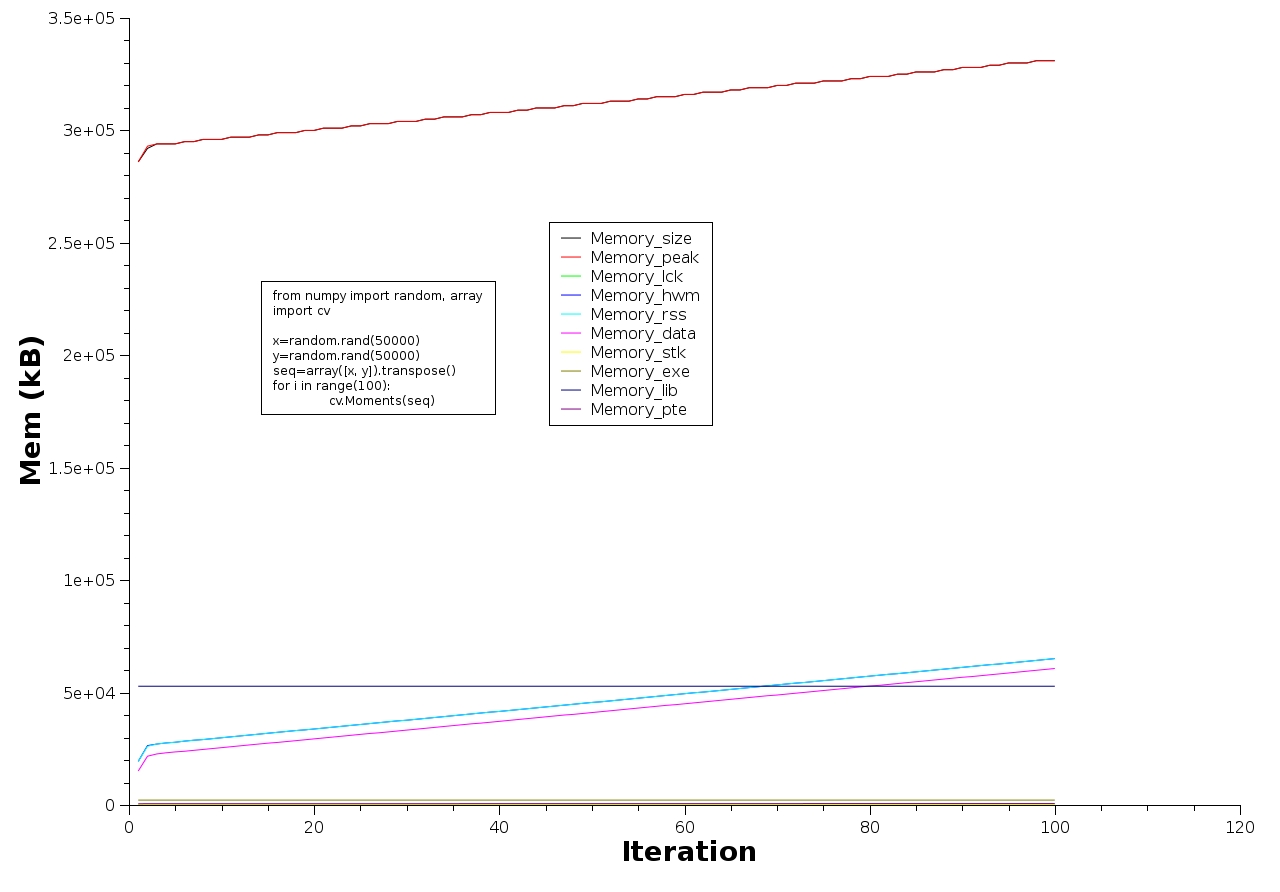
I attach a graph of the memory increasing. If you augment the iterations, it will eat up all the memory.
Compiled from SVN version 3240 on linux 64-bit and 32-bit
{kind=link}
{kind=link}
{kind=link}
Associated revisions
#489, Forbid transposed matrices in fromarray()
#489, leaking cvarrmat test and fix
Merge pull request #489 from jet47:carma-obsolete
History
Updated by James Bowman over 14 years ago
Root cause of the problem here is the numpy transpose, which is a tricky thing. Numpy transpose does not move any data, it only alters the stride of the array. In this case it gives an array with a row stride of 8 (elements are 32f) and a column stride of 40000. OpenCV was ignoring the column stride, hence getting confused. The 'fix' is for OpenCV to check that the column stride is the same as the element size, because OpenCV can only deal with arrays with contiguous data.
See http://projects.scipy.org/scipy/ticket/609 for details on transpose().
The workaround is to do transpose().copy() instead. r3398 adds a check for illegal stride.
To workaround, use copy() and cv.fromarray():
Updated by James Bowman over 14 years ago
OK, full fix in r3399. Workaround is to do:
seq=array([x, y]).transpose().copy()
- Status changed from Open to Done
- (deleted custom field) set to fixed
Updated by Daniele Paganelli over 14 years ago
I think there is something more. The copy() operation does not change anything in my case.
I suspected the interaction between numpy and opencv could cause confusion, so I also tried converting all to a list with pure python floats:
seq=list((float(elr0), float(elr1)) for el in seq)
Nothing changes: the leak is still there (svn 3393).
I'll try with 3399 and report the results.
Updated by Daniele Paganelli over 14 years ago
I'm sorry, my results refers to 3240, not 3393 as I wrote.
Updated by Daniele Paganelli over 14 years ago
Ok, problem is solved in 3399. Thank you very much for the quick help!!!
Updated by Daniele Paganelli over 14 years ago
Changing the code a little bit will uncover the memory leak again.
For example if i redefine seq at each iteration:
from numpy import random, array
import cv
x=random.rand(50000)
y=random.rand(50000)
for i in range(1000):
seq=array([x, y]).transpose().copy()
cv.Moments(seq)
While if seq is defined outside of the loop the memory does not increase.
Or if I use a standard python list [(x0,y0),(x1,y1),...] (out or inside the loop):
x=random.rand(50000)
y=random.rand(50000)
seq=array([x, y]).transpose()
seq=list((float(elr0), float(elr1)) for el in seq)
for i in range(1000):
cv.Moments(seq)
I tried with various del statements but nothing changed.
- Status changed from Done to Cancelled
- (deleted custom field) deleted (
fixed)
Updated by Daniele Paganelli over 14 years ago
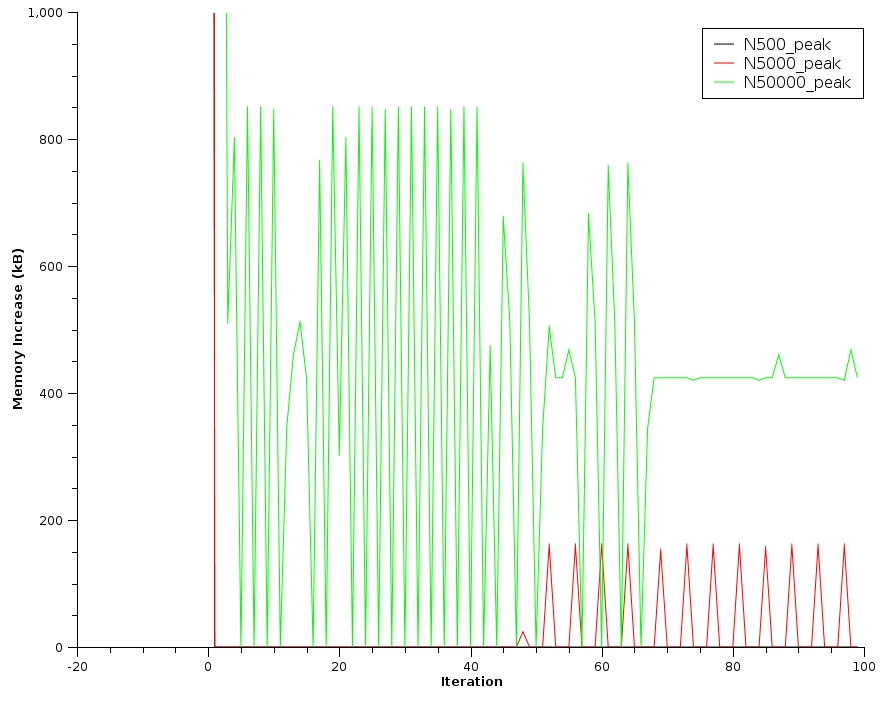
I tried to change the sequence length and found that the memory increase is not constant, for each iteration. Some iterations the memory will increase, some other iteration the memory will stay the same. The longest the sequence, the bigger and more frequent increases became. I could not find any reasonable relation between length and frequency.
I attach a graph done with this code:
As you see numpy is no longer used: only standard lists full of tuples [(1,1)] (so there cannot be interferences with numpy!).
from numpy import random, array, arange
import cv
from os import getpid
proc='/proc/%i/status' % getpid()
out='%i '*11
print 'iter peak size lck hwm rss data stk exe lib pte'
def getmem(i):
vm=open(proc).readlines()
vm=list(int(line.replace(' ', _).split(':')r1.split('kB')r0) for line in vm if 'Vm' in line)
vm=[i]+vm
return array(vm)
N=50000
for i in range(100):
vm=getmem(i)
print out % tuple(vm-vm0)
vm0=vm; vm0r0=0
seq=list((i*1., i*1.) for i in range(N))
cv.Moments(seq)
I performed 3 runs with N=500,5000,5000.
The graph is attached in leakN.jpg and shows the increase "steps": only the difference between one iteration and the next.
The black line (N=500) has no steps (apart from the first one where the mem is allocated).
The red line (N=5000) has not steps until iteration 50, then it start having one step each 4-8 iteration (it's not so regular).
The green line (N=50000) immediately has big steps, which stabilize around 500kB around iteration 70 (which means, each iteration the memory increases by 500kB!).
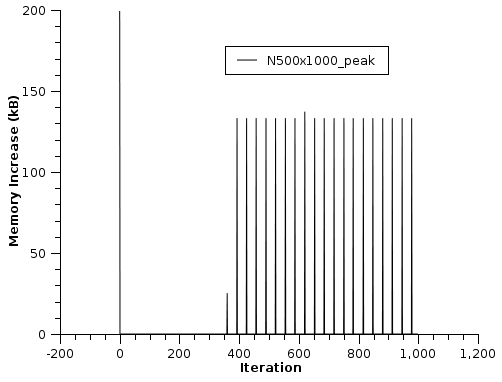
Being curious about the behaviour of the black line, I repeated the test with more iteration (1000) keeping N=500 (leak500x1000.jpg). The memory increases start appearing anyway around 400° iteration. I suspect that also an N=1 seq will eventually cause the leak, if the cv.Moments is repeated a sufficient number of times.
This behaviour is quite irregular and suggest that the leak is not deterministically caused each iteration (eg by a wrong data type or conversion, or by a python reference cycle), and its frequency depends on the length of the input data.
Updated by anonymous - over 14 years ago
I think the problem can have something in common with the leak of cv.fromarray, #493.
I tried repeating all my tests with cv.fromarray(seq) and got the same results.
The problem may be much more general, infact cv.Moments eats up memory also if a standard python list [(x,y)] is passed.
Updated by Daniele Paganelli over 14 years ago
This code confirms the previous hypothesis:
from numpy import array,arange
import cv
m=array([arange(0,100,.1),arange(0,100,.1)]).transpose().copy()
m=cv.fromarray(m)
l=list((i,i) for i in range(100))
while True:
cv.PolyLine(m,[l],0,0)
Also cv.PolyLine leaks memory.
Since m is already a cvmat and is created only 1 time, the memory increase can originate from the import of l (which is not an array, but a simple list of lists of tuples).
Updated by Daniele Paganelli over 14 years ago
See #499 for a partial solution.
Updated by Daniele Paganelli over 14 years ago
Problem is still there in 3947
Updated by Vadim Pisarevsky over 14 years ago
- Status deleted (
Cancelled)
Updated by James Bowman about 14 years ago
Fixed in r4556
Added tests/python/leak4.py
Fixed leaking cvarrseq from sequence constructor
- Status set to Done
- (deleted custom field) set to fixed